MediX-R1
Open Ended Medical Reinforcement Learning
Open source medical vision language model trained with composite reinforcement rewards.
* Equal Contribution
8B Model
Across both LLM and VLM benchmarks, outperforming the much larger 27B MedGemma .
30B Model / Best Overall
Demonstrating the effectiveness of our composite reward design across all 17 benchmarks.
2B Model / On-Device
Runs on Mobile Devices
The lightweight 2B variant is designed to run on smartphones and edge hardware, supporting on-device inference without requiring cloud access.
Benchmark Average
Across 17 medical LLM & VLM benchmarks
USMLE-SA
U.S. Medical Licensing Exam accuracy
Expert Preferred
Chosen by doctors in blind review
Training Samples
Spanning 16 medical imaging modalities
What Sets MediX-R1 Apart
The only medical VLM that combines all six capabilities: composite rewards, open-ended reasoning, and annotation-free training in a single RL stage.
*As of Feb 26, 2026
Composite RL Reward
Four reward signals (LLM accuracy, embedding similarity, format enforcement, and modality recognition) work together to prevent reward hacking and stabilize training.
Open-Ended Responses
Goes beyond MCQ to produce free-form clinical answers. LLM-as-judge and embedding rewards provide reliable feedback where string-matching metrics fail.
Interpretable Thinking
Emits structured reasoning traces in <think>...</think> blocks, enforced by a format reward. Every decision path is auditable and clinically grounded.
Single-Stage RL
No multi-step pipelines. One RL stage with group-based optimization replaces the typical pretrain → SFT → RL chain, simplifying training end-to-end.
16 Medical Modalities
X-Ray, CT, MRI, Microscopy, Ultrasound, Endoscopy, Mammography, OCT, Fundus, and more. All in a single model trained on 51K examples.
Annotation-Free
No expensive human-curated rationales needed. RL rewards operate on final answers via LLM judge and embeddings, drastically lowering data curation cost.
Benchmarks
Evaluated across 17 medical benchmarks with LLM-as-judge scoring, human expert review, and real-world clinical validation.
Overall Ranking
Average accuracy across all 17 benchmarks
| Benchmark | MedVLM-R1 2B | BiMediX2 8B | HuatuoGPT-V 7B | MedGemma 1.5 4B | MedGemma 27B | MedMO 8B | MediX-R1 2B | MediX-R1 8B | MediX-R1 30B |
|---|---|---|---|---|---|---|---|---|---|
| MMLU-Clinical | 0.540 | 0.732 | 0.721 | 0.706 | 0.879 | 0.864 | 0.660 | 0.845 | 0.894 |
| MMLU-Bio | 0.549 | 0.792 | 0.708 | 0.708 | 0.972 | 0.951 | 0.806 | 0.951 | 0.993 |
| MMLU-Med | 0.451 | 0.694 | 0.653 | 0.578 | 0.866 | 0.827 | 0.699 | 0.879 | 0.890 |
| MMLU-Genetics | 0.560 | 0.790 | 0.710 | 0.760 | 0.940 | 0.900 | 0.680 | 0.900 | 0.980 |
| MMLU-ProfMed | 0.500 | 0.695 | 0.625 | 0.768 | 0.912 | 0.890 | 0.628 | 0.868 | 0.974 |
| MMLU-Anat | 0.519 | 0.659 | 0.600 | 0.519 | 0.793 | 0.785 | 0.563 | 0.763 | 0.874 |
| MedMCQA | 0.408 | 0.572 | 0.511 | 0.538 | 0.727 | 0.662 | 0.492 | 0.683 | 0.781 |
| MedQA | 0.400 | 0.583 | 0.534 | 0.690 | 0.866 | 0.848 | 0.497 | 0.796 | 0.929 |
| USMLE-SA | 0.378 | 0.591 | 0.538 | 0.726 | 0.895 | 0.742 | 0.505 | 0.822 | 0.951 |
| PubMedQA | 0.520 | 0.520 | 0.542 | 0.460 | 0.414 | 0.586 | 0.472 | 0.482 | 0.490 |
| MIMIC-CXR-Sum | 0.704 | 0.672 | 0.707 | 0.699 | 0.767 | 0.709 | 0.739 | 0.746 | 0.765 |
| SLAKE-VQA | 0.434 | 0.468 | 0.545 | 0.565 | 0.634 | 0.479 | 0.654 | 0.703 | 0.683 |
| RadVQA | 0.404 | 0.530 | 0.614 | 0.572 | 0.585 | 0.419 | 0.539 | 0.596 | 0.625 |
| PathVQA | 0.239 | 0.323 | 0.374 | 0.332 | 0.322 | 0.272 | 0.428 | 0.455 | 0.445 |
| PMC-VQA | 0.398 | 0.482 | 0.532 | 0.474 | 0.478 | 0.360 | 0.491 | 0.554 | 0.571 |
| PMC-VQA-Hard | 0.020 | 0.229 | 0.261 | 0.258 | 0.354 | 0.177 | 0.284 | 0.317 | 0.307 |
| MIMIC-CXR-Gen | 0.240 | 0.124 | 0.316 | 0.273 | 0.224 | 0.084 | 0.280 | 0.328 | 0.350 |
| AVG | 0.427 | 0.556 | 0.558 | 0.566 | 0.684 | 0.621 | 0.554 | 0.688 | 0.736 |
Best and second best results are bold and underlined. Top section: LLM (text-only) tasks. Bottom section: VLM (image+text) tasks.
Expert Preferred
72.7%
Blind preference from doctors
Model Architecture
A reinforcement learning framework that teaches medical AI to think, not just memorize.
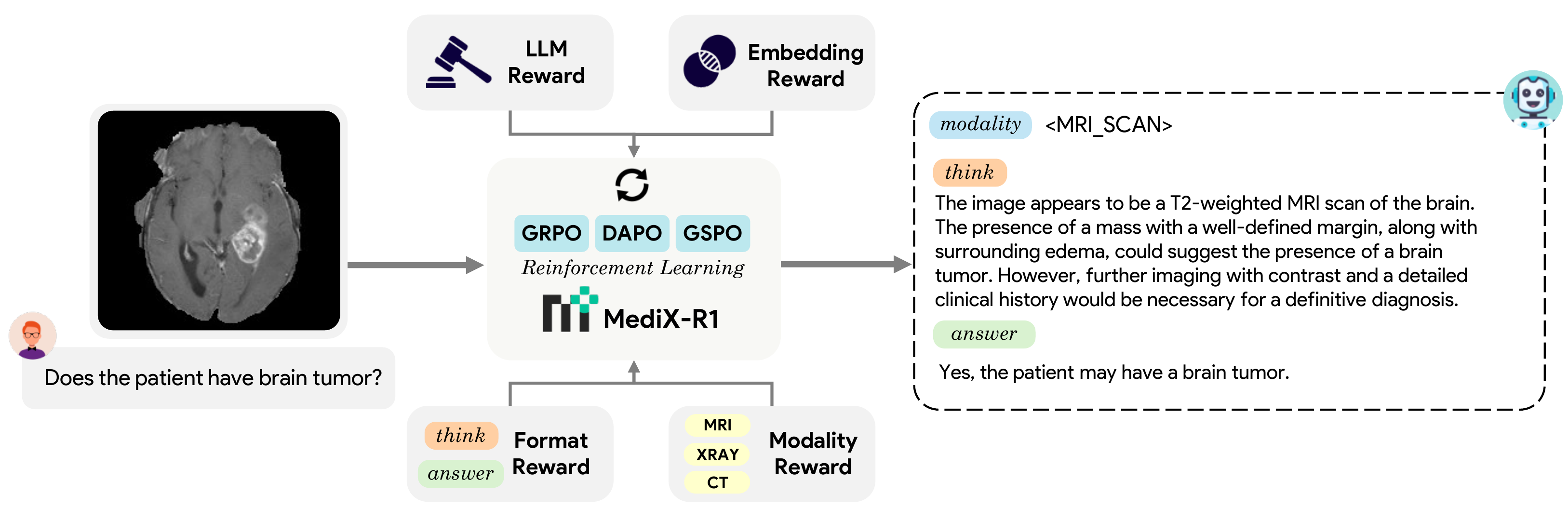
Qualitative Examples
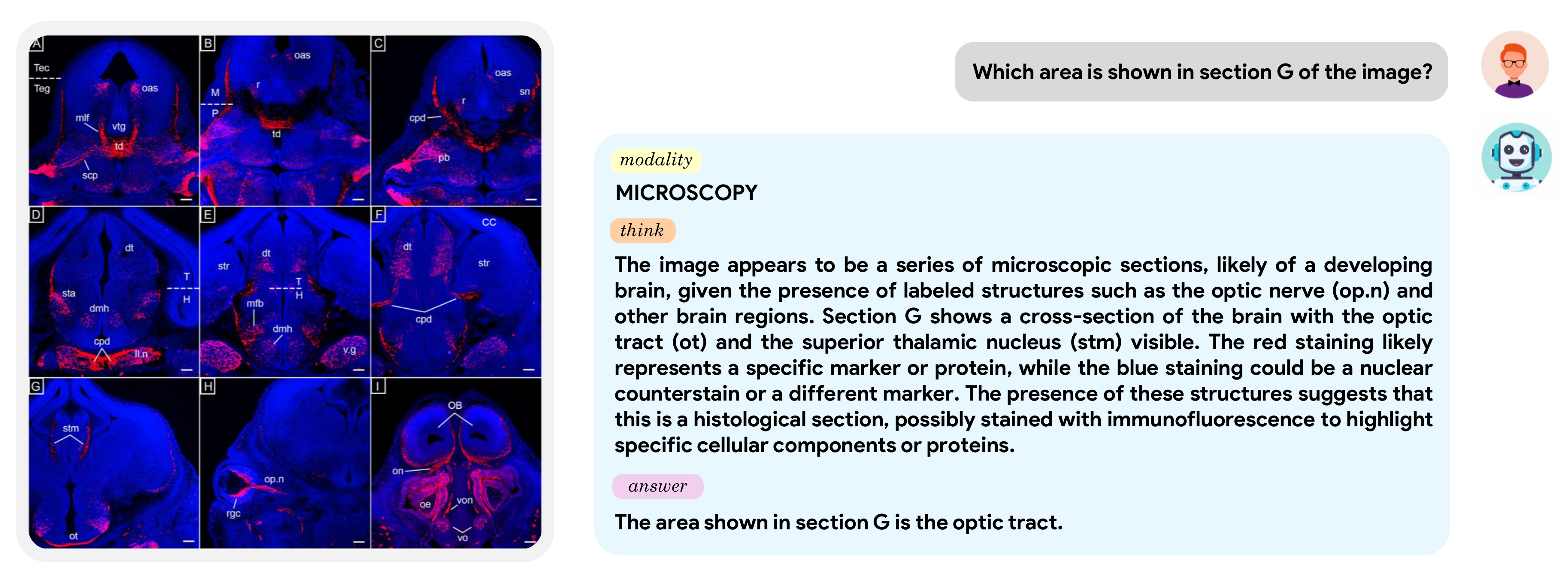
MediX-R1 correctly identifies the optic tract in a histology cross-section, providing step-by-step reasoning grounded in the visual features of the image.
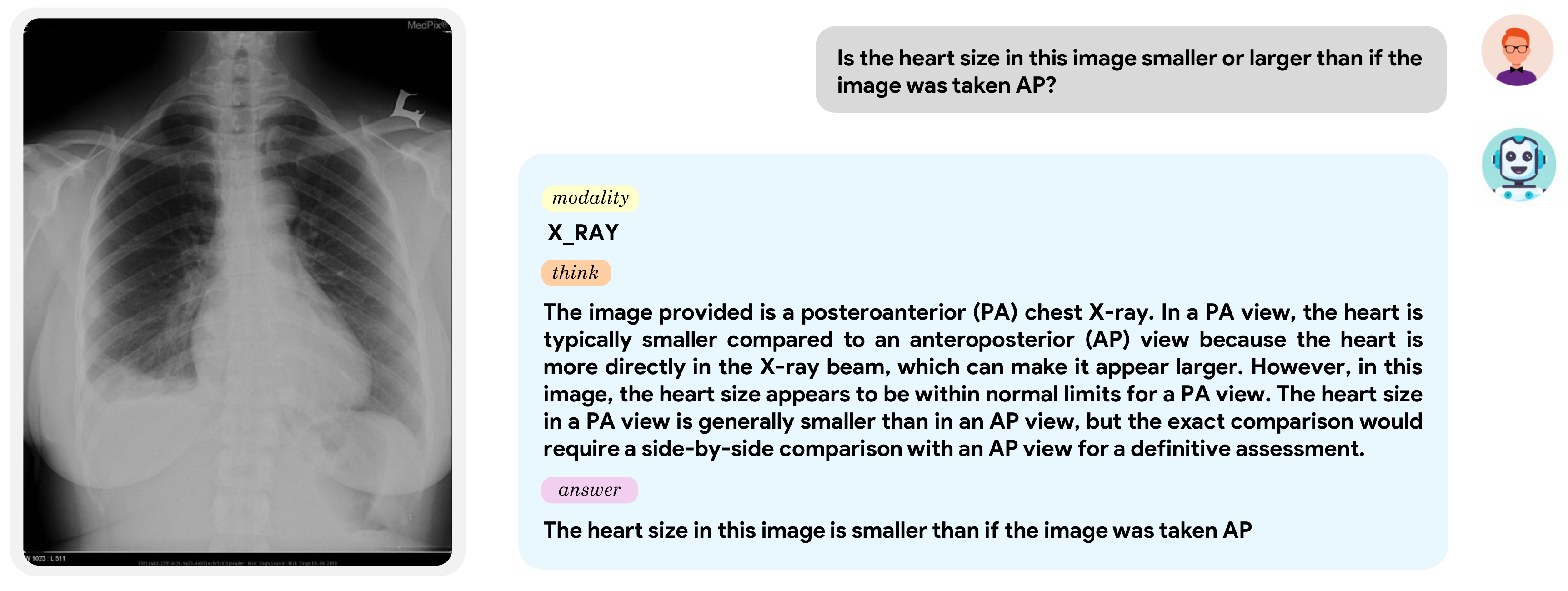
Given a chest X-ray, MediX-R1 explains why heart size appears smaller in PA versus AP projection, demonstrating real clinical understanding, not pattern matching.
Composite Reward Design
Training with individual reward signals (LLM-only or embedding-only) leads to instability and reward hacking. Combining LLM + embedding reduces volatility but doesn't eliminate it. MediX-R1's composite reward, blending accuracy, semantic, format, and modality signals, stabilizes learning and delivers the highest final performance.
Evaluation Framework
Batched inference via vLLM
Model processes input
Generates structured responses
Persists full output per sample
Example Input
Model Output
<MICROSCOPY>
<think>...reasoning...</think>
<answer>
Low blood flow or less perfusion
</answer>
Reference-based LLM-as-judge
BASE template for QA/MCQ
MIMIC template for reports
Binary decisions & rubric scores
Ground Truth (GT)
Candidate Answer (CA)
Judge Comparison
✔ GT and CA are semantically aligned
✔ CA is clinically appropriate to GT
Aggregate to dataset metrics
Mean accuracy for binary eval
Average rubric scores
Macro averages across benchmarks
Binary Decision
Final Score
A three-stage pipeline: (1) Generate answers via vLLM inference, (2) Evaluate using a Reference-based LLM-as-judge with BASE and MIMIC templates, and (3) Aggregate scores. Supports binary decisions for QA/MCQ tasks and rubric-based scoring for long-form clinical reports.
Citation
If you find MediX-R1 useful, please cite our work.
@misc{mullappilly2026medixr1openendedmedical,
title={MediX-R1: Open Ended Medical Reinforcement Learning},
author={Sahal Shaji Mullappilly and Mohammed Irfan Kurpath and Omair Mohamed and Mohamed Zidan and Fahad Khan and Salman Khan and Rao Anwer and Hisham Cholakkal},
year={2026},
eprint={2602.23363},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2602.23363},
}Acknowledgment
This work was partially supported with NVIDIA Academic Grant 2025 and MBZUAI-IITD Research Collaboration Seed Grant.